
I spent three months building a system that reads thousands of contracts and flags where they disagree with their company’s vendor master. The LLM call took an afternoon to get working. Everything around it took the rest of the time.
If you’ve shipped anything AI-adjacent, that won’t surprise you. If you haven’t, it’s worth saying out loud: for this kind of work, the model is interchangeable. We didn’t fine-tune. We barely cared which provider we used. The hard work was deciding what counted as a discrepancy, getting clean structured data out of long messy PDFs with receipts attached, and surviving a pipeline that had to run for three weeks straight inside someone else’s rate limits.
In the end the system processed over 30,000 documents across thousands of contracts at ~96% extraction accuracy on the labeled set. The output was a stack of dashboards that quantified the dollar impact of every payment-term mismatch, expired-but-active contract, and date conflict between the contracts and the master.
This is the story of how the project actually went, written for backend engineers. The LLM call is a paragraph; the systems decisions around it are everything.
In short: the project was not hard because of prompting. It was hard because contracts are messy, upstream metadata lies, rate limits shape the architecture more than the algorithms do, and extracted fields are worthless until they’re normalized, audited, merged, and tied back to business rules. The model was an afternoon. Everything else was three months.
Table of contents
- The real problem took a while to find
- 75% wasn’t going to cut it
- Normalization is part of accuracy
- Then the data showed up
- The first architecture I drew was nonsense
- Processing the same document twice
- Rate limits were the real bottleneck
- Merging is the actual job
- Redash, not a UI
- What I’d change
- What stuck
The real problem took a while to find
The client showed up with a wishlist: a UI, accounts, RBAC, SSO, “an AI for our contracts.” Three meetings in, nobody could finish that last sentence. They were certain about the UI. They were not at all certain what the AI was supposed to do.
The actual problem came out slowly. They had a vendor master (the system of record for every supplier they paid) and they had thousands of contracts sitting in a CLM. The two disagreed in ways nobody had catalogued. Payment terms didn’t match. Vendors marked active had expired contracts on file. Contracts referenced amendments the master never picked up. A 30-day vs 45-day payment term, multiplied across a few hundred thousand dollars of annual spend, is real money leaking every quarter.
I made the case that the UI wasn’t the highest-leverage thing in phase one. The job was: read every contract, pull the fields that mattered, line them up against the master, flag the differences. The UI went on the shelf.
I spent two days with raw Gemini and OpenAI APIs to feel out the problem. Then I went looking for something that could chunk long documents and attach a source span to every extracted field. Hallucination was off the table. The output was going to finance, and every value had to be traceable back to the snippet it came from. I found LangExtract. It did exactly that.
Why this mattered. The client did not need extracted text. They needed defensible decisions. Every value had to survive the question: “Where did this come from?” Picking a library that returned source spans by default (instead of bolting traceability on later) meant provenance became a property of the data model, not a feature we’d have to retrofit when the first finance reviewer asked.
I wired it into a small Streamlit POC, processed the sample contracts, and brought the result to the next sync. The client had brought in a couple of product consultants by then, and Chris was running point on their side, the bridge between procurement and us. The POC wasn’t there to look impressive. It was there to make the conversation specific. Once the room could see actual extractions next to actual snippets, the meeting stopped being about “an AI for contracts” and started being about whether vendor_name should include a legal “d/b/a” suffix and what to do when the effective date and the signature date disagree. The spec started writing itself.
75% wasn’t going to cut it
The first real run used a single prompt: every document type, every field, all in one place. Accuracy came back at 75%.
That number didn’t move much no matter how I tightened the instructions. The model was confusing rules across document types: amendment guidance bled into contract extractions, summary-sheet rules contaminated everything else. The prompt was also expensive in a stupid way: every document carried instructions for every other document, regardless of what we were actually looking at.
I split it. One prompt per document type, five in total. Each one got specific. The contract on the client’s paper got a priority order for the effective date: opening paragraph first, term section second, signature date as a last-resort fallback. Vendor names got their own block of edge cases for legal aliases. Amendments got loud warnings not to confuse the original agreement’s date with the amendment’s own effective date. Form-style documents got rules for label-value pairs; tabular documents got rules for pipe-separated cells. Each prompt knew what document it was reading.
Why this mattered. Prompts are inputs to a black-box function whose accuracy degrades silently when those inputs collide. One prompt per document type isn’t a prompt-engineering trick; it’s blast-radius control. Tightening amendment rules can’t regress contract extractions, because they’re now different functions. The same instinct backend engineers apply to coupled deploys applies to coupled prompts.
I also built an eval harness, which I should have built three weeks earlier. Hand-labeling a few dozen contracts and grading every prompt change against them turned every “this feels better” into a number. The trajectory was 75 → 85 → 92 → eventually ~96. We landed.
Why this mattered. Without a metric, every prompt change is a vibe, and you can’t tell improvement from regression. The eval harness closed the loop. It turned prompt engineering from a creative exercise into something that looked like every other system you tune: change, measure, decide. If you take one thing from this section, take this one.
What 96% actually means here is worth saying. It’s not that we extracted every field correctly. It’s that the fields we did extract were correct, and the fields we couldn’t extract confidently were left null with a needs_review flag. We tuned the system to abstain rather than guess. For finance, a missing field is a much cheaper error than a wrong one.
Why this mattered. Failure modes have asymmetric costs, and the system should know which side of the asymmetry it’s on. A wrong number on a finance dashboard is read as truth and acted on; a null with a flag is read as work. We chose to fail visibly because the alternative was failing silently into someone’s quarterly reporting.
Normalization is part of accuracy
Even with a clean prompt, the model returns strings: different ways of writing the same payment term, different ways of writing the same date, OCR-mangled spellings of both. The model returns what’s in the document; it doesn’t return anything you can compare with a SQL =.
So after extraction, every field runs through a normalizer. Payment terms collapse into a small set of canonical codes via a lookup table that grew every time a document found a new way to write the same thing. Dates get parsed, including a small dictionary of OCR-typical typos. Currency strings become numbers. Vendor names get a normalized form for comparison without losing the original.
Normalization isn’t glamorous, and it’s easy to skip on the way to “we have AI extraction.” It’s also the layer that makes the rest of the system honest. Every extraction result carries the normalized value, the raw string, and a list of warnings; those warnings then propagate into tags downstream, so a value that had to be coerced doesn’t quietly become canonical truth.
Why this mattered. “96% extraction accuracy” doesn’t survive a SQL join if the strings on either side of the = were never the same shape. Normalization is the boundary between the LLM’s view of the document and the database’s view of the world, and it has to be a real layer with its own tests, its own logs, and its own warnings carried forward as data, not as side comments.
Then the data showed up
For weeks nobody could tell me how the bulk data would arrive. Best case: organized folders, one per contract. Worst case: a flat dump of tens of thousands of files where I’d have to reconstruct contracts by matching identifiers and fuzzy vendor names.
I built insurance for the worst case: Elasticsearch, name normalization, the usual suspects. None of it was going to be clean. In the end the data showed up neatly: SFTP, files organized by document type, a CSV that linked each document to a contract record and a vendor. I wired up SFTP-to-S3 sync, and the fuzzy-matching plan sat unused on a branch.
Then the data started misbehaving.
The CSV’s stated document type was wrong often enough that we couldn’t trust it. A row labeled AMENDMENT would point to a file that was actually a summary sheet. We added a second-pass classifier (Gemini Vision on the first page of every PDF, with filename-pattern matching for the non-PDF files) and treated the CSV as a hint rather than the truth.
Why this mattered. Trusting upstream metadata is a single point of failure with no observability: when it’s wrong, every downstream stage runs the wrong prompt and produces correct-looking garbage. The classifier turned an unverifiable assumption into a verifiable signal, and gave us a place to log disagreements between what the CSV claimed and what the document actually was. That log later became one of the more useful debugging artifacts in the system.
The CLM also had several files with identical names, which the file system can’t represent. The export had silently appended a sequential ID with a leading dash to disambiguate, and I had to write a script to walk the dump and re-link them by ID before any of the rest of the pipeline would work.
DOCX files couldn’t be classified by Vision at all. They fell back to the CSV’s stated type. We accepted the risk and moved on.
Lesson: treat upstream metadata as a hint, not as truth. I treated it as truth at first, and paid for it.
The first architecture I drew was nonsense
By the time the data was in S3 and the prompts were tuned, I needed to figure out how to run the pipeline against tens of thousands of documents reliably. I drew a first version of the architecture. It had boxes for components I hadn’t decided on yet and arrows that didn’t really commit to anything.
The point wasn’t to be right. The point was to give us something concrete to argue about. Within a week the queue had become a workflow engine and the per-stage shape had emerged. The first sketch is supposed to be wrong. Its job is to be specific enough that the next sketch can be better.
I’d been imagining, at first, a queue and a pool of workers. My CTO suggested I look at Temporal. The more I read, the more it fit.
A few things made queue-plus-workers feel wrong. Some documents were going to take hours, not because the LLM was slow, but because the daily quota would run out partway through and the workflow would need to wait until 9 AM UTC the next day to continue. No queue I’d write would model that cleanly. Different stages of the pipeline (parsing, classification, extraction, normalization, persistence) wanted different concurrency limits and different retry behavior, and trying to express that in queue topology gets ugly fast. And every retry, every failure, every “why did this document skip” question was eventually going to land on me, three weeks after the fact, asking the system to tell me what happened.
Temporal handles that. Every document becomes a workflow with durable state. Each stage runs as an activity on its own task queue, with its own worker pool, its own concurrency cap, and its own retry policy. When something fails, the workflow history is right there, replayable, debuggable. When a worker dies mid-extraction, the activity reschedules itself and any external resource it was holding (in our case, a quota lease) reclaims itself on a TTL.
Why this mattered. When a pipeline runs for weeks against an external rate limit, the operating question stops being “did it process” and becomes “what happened, why, when, and can we replay just the part that broke.” A bare queue answers none of those without bespoke instrumentation. Temporal answers all of them by default. Workflow history is the instrumentation. We were paying for an SDK and operational overhead, but what we got back was the audit log we would have had to build anyway.
I won’t pretend Temporal is free. It’s another system to operate, the SDK has its own learning curve, and you have to think carefully about workflow determinism in ways you don’t with normal code. For a one-shot batch, a queue and a script are fine. For a pipeline that has to run for weeks, gracefully handle external rate limits, and be debuggable months later, the cost is worth paying.
The architecture, at its simplest, ended up like this:
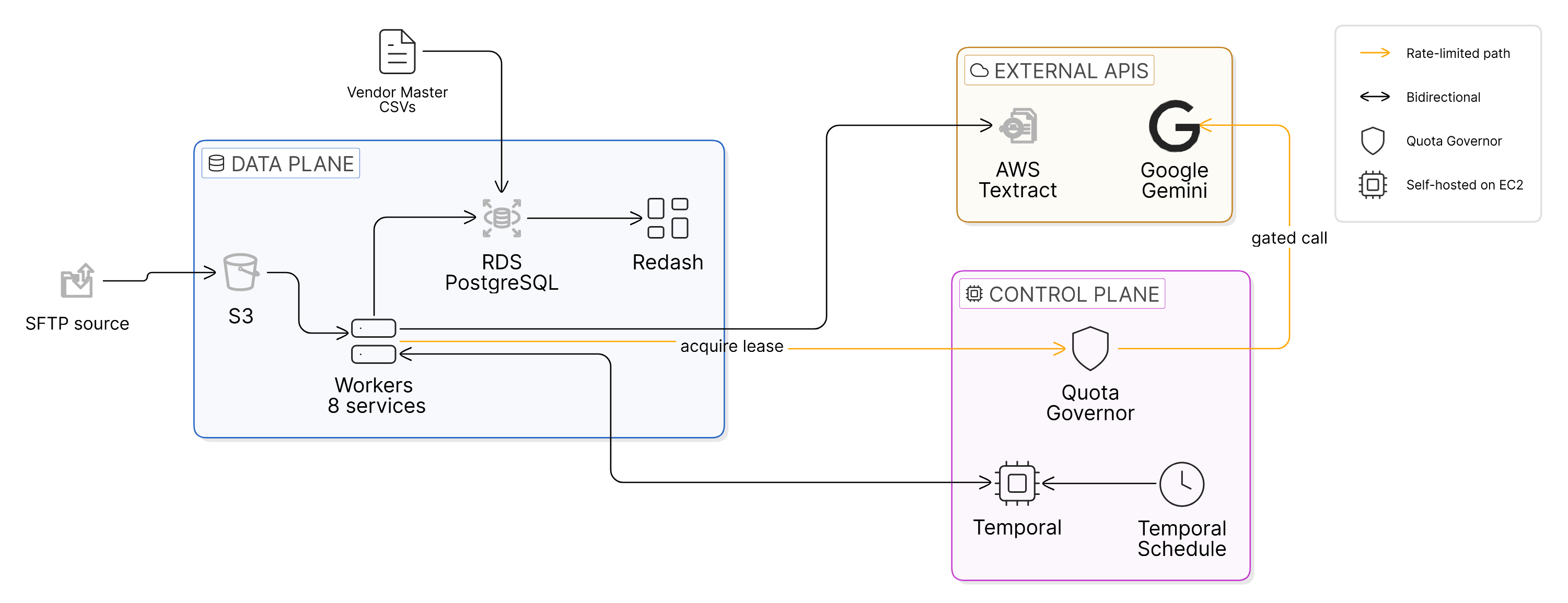
Eight worker pools, one per stage, each on its own task queue. A Temporal Schedule ticks every ten minutes, looks at how many extraction workflows are running, and starts as many new ones as it takes to hit a target, about a hundred in flight at any moment. We never push the full 30,000+ documents into Temporal at once. The system behaves like a steady stream that’s easy to throttle, easy to pause, and easy to reason about. Slowing the run down is a config change.
Why this mattered. Two decisions are doing a lot of work here. Per-stage worker pools mean each stage has its own concurrency cap and retry policy: extraction’s failure modes don’t compete with persistence’s failure modes for resources, and we can scale them independently. Scheduler-based admission means the in-flight count is a knob, not a consequence; if the API starts misbehaving at 3 AM, the response is one config change, not a code deploy. We turned “how fast does this run” into a tunable parameter rather than an emergent property.
Processing the same document twice
Somewhere between drawing the schema and running anything serious through it, I made a choice that I keep being grateful for: an extraction result is not the same row as a record of processing the document. Each document gets a new processing_run every time it goes through the pipeline, and each run produces (or fails to produce) its own extraction_result. The old runs stay.
This sounds like an over-engineering tax until the third time you have to re-run something. New prompt? New run, old runs preserved, side-by-side comparison in SQL. Quota governor terminated and we lost a day’s worth of work? The runs that succeeded are still there; we only re-process the ones marked failed. A wrong document type slipped through and we want to redo only the affected files? Filter and reprocess. The original run sits there as a record of what we used to think.
Why this mattered. The data model has to make re-running cheap, because in a system this size you will re-run. If the schema confuses “the document” with “an attempt at processing the document,” every backfill becomes a destructive write, and destructive writes mean you lose the ability to A/B compare prompt versions, to bisect when a regression appeared, to ask “what did we believe last Tuesday.” Append-only history isn’t an extravagance for a long-running ingestion pipeline; it’s the difference between debuggable and not.
The same idea shows up in the merge layer: for every field on a merged contract record, we store which extraction result it came from. So when a finance reviewer asks “where did this payment term come from,” there’s a path back to a specific document, on a specific run, on a specific date. The auditability that gated the project lives in this row.
Rate limits were the real bottleneck
Once the pipeline survived a few hundred documents, we ran the math on the full corpus.
Over 30,000 relevant documents. Long contracts get chunked into multiple LLM requests, so we averaged roughly 5,000 requests per 100 documents. Total: over 1 million LLM requests for the full run.
On Tier 1 of Gemini’s quota (10,000 requests per day), that’s 100 days. Over three months. On Tier 2, with 100,000 per day, it drops to 10. Same code. Different limits. Most of the production run’s calendar time was waiting on quota, not on compute.
Living inside someone else’s rate limit shaped a lot of the design. I built a quota governor: a single durable workflow per model that holds the bucket of available requests, the daily counter, and any active leases. Every extraction acquires a lease before calling the API. If the bucket is empty, the workflow comes back later. If Gemini returns a 429, the activity tells the governor to apply a cooldown, and every other extraction in flight respects it. The governor’s state is durable; it survives worker restarts. When the daily counter resets at 9 AM UTC, every workflow that was waiting wakes up.
There was a temptation, when the first admission-gate problems showed up, to reach for Redis as a sidecar; a token bucket in Redis is a five-line solution. I didn’t, and I think that was right. Keeping quota state inside Temporal meant one fewer system to operate, one fewer place for state to drift, and the workflow history doubled as an audit log of every quota decision. The cost showed up as retry-loop ergonomics on the client side. Trade I’d take again.
Why this mattered. Every additional system has a recurring cost: it has to be deployed, monitored, secured, restored. A token-bucket-in-Redis is five lines on day one and an extra page in the runbook for the next two years. Keeping the bucket inside Temporal turned “what happened to this document’s quota lease” into a question the existing workflow history already answered. Operational simplicity is a feature you pay for in code, not in infra.
The governor came with two specific lessons I had to learn the hard way.
First, Temporal limits each workflow execution to a couple thousand updates, and the governor handles thousands per day. We hit the ceiling within twenty-four hours of the first real run. The fix was continue-as-new: the governor checks is_continue_as_new_suggested() every update, serializes its state, and re-runs itself when Temporal asks. You only encounter this problem if you let a single workflow handle bursty load over long horizons. We did.
Second, under bursty load dozens of activities would try to update the governor at the same instant, and a few would come back with “concurrent in-flight updates” errors. We added jittered retries on the client side with a budgeted retry window. Both of these are documented Temporal behaviors. Both required reading the docs more carefully than I had the first time around.
And then there was the timeout. The first version of the system had a generous extraction timeout of an hour or two, which meant a workflow that hit the daily ceiling at noon UTC would die before it could continue at 9 AM the next morning. I pushed that timeout to 25 hours, long enough to survive a full quota cycle. Anyone reading the constant cold thinks 25 hours is absurd, so that one needed a comment in the code, a comment in the README, and probably a third comment for whoever inherits this someday and tries to “fix” it.
Merging is the actual job
Extraction gives you fields. The business question lives at the contract level, and a single contract has an executed version, often an amendment, and one or two summary sheets, and they don’t all agree.
Deciding which document to trust for which field turned into its own small project. The default rule we settled on, after a few rounds with the product consultants:
- A newer amendment overrides the executed contract. Otherwise the executed contract wins.
- Among executed contracts, vendor paper outranks the client’s own paper, because the client’s paper has been re-keyed at least once and re-keyed data is suspect.
- Fields that don’t appear in contracts at all (projected annual spend, for example) fall back to the summary sheet.
- Vendor name and vendor ID ignore the hierarchy entirely. Those values have to match the master, and the master is populated from the same summary sheets, so we always pull them from there.
One subtle rule we learned the hard way: dates and term length must come from the same document. Otherwise you can claim a contract started in 2024, ran for three years, and ended in 2026, which is what happens when you take the effective date from one source and the term from another. We lock those three together.
Why this mattered. Per-field merge precedence is correct in the small and wrong in the large, because some fields are coherent only as a set. Treating start date, term, and end date as independently mergeable produces output that’s individually defensible and collectively nonsense. Whenever a system merges fields independently, ask which subsets have to travel together.
After merging, we compare against the vendor master and flag every difference. Early on the obvious move was a single status column: OK, MISMATCH, NEEDS_REVIEW. We didn’t use one. A contract can have a payment-term mismatch and an inactive vendor and a missing summary sheet, all at once, and they’re all independent facts. Reducing them to one status throws information away. So we use tags. Arrays of them, on both per-document and per-contract records. Document-level tags answer “is this document, by itself, OK?” Contract-level tags answer “is the merged result coherent and consistent with the master?” They’re additive; nothing replaces anything. Almost everything the client cares about flows through these tags. Every dashboard ultimately filters by one.
Why this mattered. A status column is a lossy encoding of a multi-dimensional answer. Whenever new dimensions appear (a new check, a new flag, a new failure mode), a status enum either grows ugly or starts hiding facts behind precedence rules. Tags are additive and stable: adding a check is a new tag, not a schema migration. The data model has to anticipate that the list of things you care about will grow, even if any individual thing you care about is fixed.
Redash, not a UI
The deliverable, in the end, looks like a stack of Redash dashboards backed by a few SQL views. “All contracts where the merged payment term differs from the master, with annual spend impact.” “All contracts whose summary sheet contradicts the contract on expiration date.” “All vendors marked active with no current contract on file.”
Building a custom UI for views that are fundamentally tables would have been weeks of frontend work for not much benefit. Redash gave the client something to look at the same week we had data to show. If the analyst workflow ever outgrows it, that’s a problem for phase two.
What I’d change
A few things look obvious in hindsight.
The eval harness should have been the first thing I built, not the third. Every prompt change before it was vibes. Once it existed, every change was a decision.
I should have treated the CLM’s metadata as untrusted from day one, not the day after the wrong document types broke a run. The second-pass classifier is now load-bearing, and if I’d built it earlier we’d have skipped a re-extraction.
The merge precedence rules and tag definitions are scattered across activity code, enums, and a markdown doc that’s mostly truthful. They want to live in a config file. The next phase, if it happens, takes the system from “this client’s contracts” to “any client’s contracts,” and most of that work is pulling those rules out of code: document-type taxonomy, prompt bundles, precedence ranks, tag definitions, vendor-master schema mapping. The pipeline shape is right; the wiring is what’s hardcoded.
And we should have asked the client to upgrade their Gemini tier before the production run, not during it. Same code. Eighty-five days became nine.
What stuck
Almost none of the difficulty was in the model.
We didn’t fine-tune. We didn’t even particularly care which provider we used; the same prompts produced reasonable output on more than one. The hard work was deciding what counted as a discrepancy, trusting the data only after we’d verified it, building a pipeline that could be paused and resumed and replayed and audited, carrying every field’s source through extraction and merging and into the dashboard so that “where did this number come from” always had an answer, and figuring out what the client actually meant when they said they wanted a UI.
The interesting engineering problems in this kind of work aren’t AI problems. They’re systems problems wearing AI clothing: durability, idempotency, blast radius, provenance, admission control, append-only history. Every one of them would have been a hard problem in a system that never called an LLM.
The model is the easy part.